Java 26 新特性:G1 GC 吞吐量优化(JEP 522)

JEP 522 的核心改进在于写屏障(Write Barrier) 的精简与卡表(Card Table) 机制的优化。如果你对 G1 的并发标记和记忆集(RSet)管理已经有一定了解,那么理解下面这些改动会更加顺畅:
| 维度 | 改进前 | 改进后 |
|---|---|---|
| 写屏障 | 复杂的同步逻辑,包含“优化卡表”相关指令 | 简化为类 Parallel GC 风格,仅标记卡表“脏” |
| 同步方式 | 应用线程与 GC 优化线程持续协调 | 引入双卡表,双方各自操作,互不干扰 |
| 性能影响 | 同步开销降低吞吐量,增加延迟 | 吞吐量提升,GC 暂停时间更可控 |
接下来,我将从 JEP 的基本信息开始,带你逐步解析这次优化的背景、动机以及它如何从根本上改变 G1 的工作方式。
基本信息卡片
| 项目 | 内容 |
|---|---|
| JEP 编号 | 522 |
| 标题 | G1 GC:通过减少同步来提升吞吐量 |
| 所属版本 | JDK 26 |
| 状态 | Closed / Delivered |
| 类型 | Feature |
| 组件 | hotspot / gc |
| 负责人 | Ivan Walulya |
| 创建时间 | 2024/09/24 |
| 关联 Issue | JDK-8340827 |
历史版本:JEP 522 已于 JDK 26 中交付。
目标:减少 G1 垃圾收集器的同步开销;缩小 G1 写屏障的注入代码量;保持 G1 整体架构不变,不影响用户交互。
非目标:并非让 G1 在吞吐量上完全追平其他吞吐量优先的收集器(如 Parallel GC)。
背景与动机:G1 的“甜蜜负担”
G1 是 HotSpot JVM 的默认垃圾收集器,其设计目标是在延迟和吞吐量之间取得平衡。但与 Parallel 这类吞吐量优先的收集器相比,G1 为了换取更低的延迟,将大量工作转为与应用程序并发执行。这不可避免地带来了副作用:
- 资源共享:应用线程必须与 GC 线程共享 CPU 时间。
- 同步开销:并发工作的线程之间需要进行大量的协调与同步。
这些同步操作不仅会拉低整体的吞吐量,甚至会反过来增加延迟。JEP 522 的目标,正是通过减少这种不必要的同步,来同时提升吞吐量和降低延迟。
要理解这次优化,我们需要先回到 G1 内部的两个关键机制:卡表 和 写屏障。
G1 如何追踪对象引用?—— 卡表与写屏障
G1 回收内存时,会将存活对象复制到新的内存区域。在此之后,所有指向这些对象的旧引用都需要更新到新地址。为了高效地找到这些需要更新的引用,G1 并没有扫描整个堆,而是依赖一个名为 卡表(Card Table) 的数据结构。
- 卡表:它将整个 Java 堆划分为许多固定大小的“卡片”。当某一区域的对象引用了另一区域的对象时,对应区域的卡片就会被标记为“脏”。
- 写屏障(Write Barrier):这是 JIT 编译器在应用程序代码中注入的一小段指令。每当代码执行引用类型的赋值操作时,写屏障就会执行,负责更新卡表,标记相应的卡片为“脏”。
优化卡表的代价:沉重的同步
对于某些频繁分配新对象并赋值引用的应用来说,卡表会迅速膨胀,导致 GC 暂停时扫描卡表的耗时超出预期。为了解决这个问题,G1 引入了后台的“优化线程”来在并发阶段清理和优化卡表。
然而,问题也随之而来:应用线程和优化线程都会操作同一张卡表,为了避免冲突,它们之间必须进行复杂的同步。
这导致了两个直接后果:
- 复杂的写屏障代码:为了配合同步机制,注入到应用中的写屏障代码变得臃肿且低效。
- 复杂的优化代码:优化卡表的代码同样因为要处理同步而变得复杂。
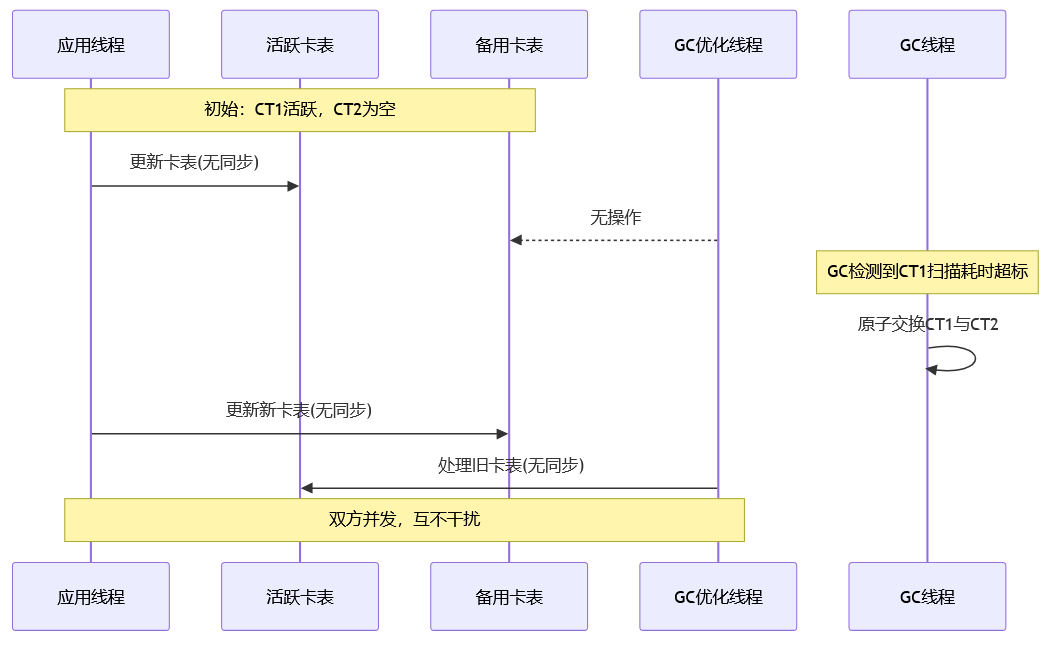
核心变更详解:双卡表机制
JEP 522 的解决方案非常巧妙:既然冲突源于大家共用一张表,那就引入第二张卡表,让双方各司其职。
解决方案:双卡表交替工作
- 应用线程:它们只更新第一张卡表。由于没有优化线程的干扰,写屏障代码被极大地简化,变得像 Parallel GC 的写屏障一样高效。这可以说是本次优化最大的性能提升点。
- 优化线程:它们则专心处理第二张卡表,而这张表在初始时是空的。
- 原子交换:当 G1 在 GC 暂停期间预测到,扫描当前的应用卡表可能会超过暂停时间目标时,它会原子性地交换这两张卡表。
- 角色互换:交换后,应用线程转而更新那张新的、空的卡表,而优化线程则从容地处理那张已经写满数据的旧卡表,整个过程无需任何额外的同步。
下面这张示意图清晰地展示了双卡表交替工作的全过程。

关联 JEP 与相关背景
在优化并发性能的道路上,JEP 522 并非孤立的存在。它与 Project Loom 的思想一脉相承:消除重量级的同步操作,是提升并发系统性能的关键路径。
此外,你可能会联想到 JDK 24 中交付的 JEP 483(Ahead-of-Time Class Loading & Linking)。两者的目标恰好互补:
| JEP | 关注阶段 | 核心目标 |
|---|---|---|
| JEP 483 | 启动与热身 | 缩短启动时间 |
| JEP 522 | 稳定运行 | 提升吞吐量,降低延迟 |
兼容性与影响
JEP 522 是一次底层优化,对用户透明。
- 无需代码改动:开发者无需修改任何应用代码。
- 无需 JVM 参数调整:此优化默认生效,无需额外的启动参数。
- 行为不变:G1 的整体架构和用户交互方式保持不变。
不过,社区在测试期间也观察到了一些性能波动,例如在某些压测场景下出现过吞吐量回退,以及在 Tools-Javadoc-Steady 基准测试中有约 1-4% 的性能下降。OpenJDK 团队已对这些回归问题进行了深入分析和修复,确保最终版本的稳定性。
小结
JEP 522 通过引入双卡表,从根本上消除了 G1 垃圾收集器中应用线程与 GC 优化线程之间的同步开销。这使得 G1 的写屏障变得像 Parallel GC 一样精简,为所有使用 G1 的 Java 应用带来了一次“无感”但切实的性能提升。
对于那些对延迟敏感、且对象引用操作频繁的应用来说,这项优化的收益尤为明显。它的设计思路也为后续的 GC 优化提供了新的方向:用空间换时间,通过巧妙的数据结构设计来消除并发瓶颈。
随着 Java 平台持续演进,这种减少同步、提升并发效率的优化将成为主流趋势。