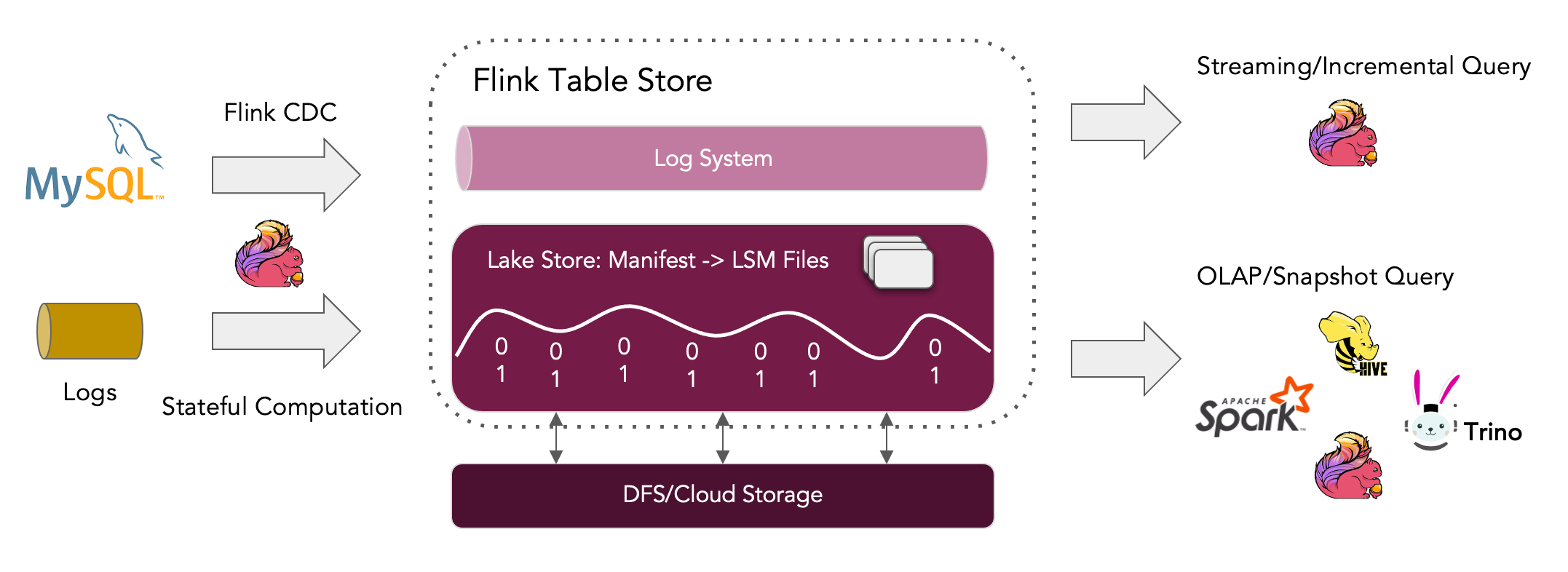
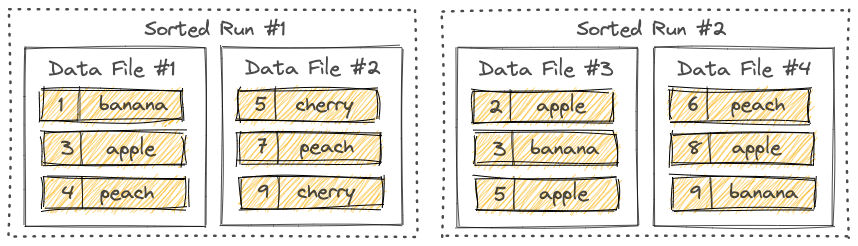
Apache Flink的核心特性
在大数据和实时数据处理的时代,Apache Flink 以其卓越的性能和灵活性成为了业界的明星。本文将深入探讨这款框架的核心特性,以帮助我们更好地理解其在大数据分析和实时数据处理方面的优势和应用场景。
批流一体
Flink 采用了统一的流处理架构,可以用相同的编程模型和运行时系统支持有界数据的批处理和无界数据的实时流处理。这种设计理念使 Flink 在企业技术选型中具有重要意义:
首先,Flink 消除了批处理和流处理之间的鸿沟,企业无需再采用多套框架分别实现两者。这简化了架构设计,降低了系统复杂度。其次,统一的编程模型可以重用批处理和流处理的代码逻辑,提高开发效率。开发人员无需学习多种编程模型,大大减少了学习和开发成本。最后,单一的运行时系统简化了运维工作,无须部署和维护多套框架,可以节省大量运维成本。
也就是说,Flink 的统一流处理架构为企业提供了一个高效、灵活、易于使用的大数据处理解决方案。如果 Flink 能够满足业务需求,就无须用两种甚至多种框架分别实现批处理和流处理,这大大降低了架构设计、开发、运维的复杂度,可以节省大量人力成本。这是 Flink 相比其他框架的一个重要优势。
复杂的状态管理
Flink 支持有状态计算。Flink 原生的分布式一致状态管理机制,为状态密集型应用提供了稳定可靠的状态存储和访问接口,可以支持各种复杂的有状态计算应用。这是构建实时数据应用的关键能力之一。
多种时间语义
Flink 提供了事件时间(event-time)和处理时间(processing-time)两种语义,这使其在处理乱序事件流时能够提供一致且准确的结果。在流处理中,数据到达 Flink 系统的顺序可能与事件本身发生的时间顺序不一致,这是很常见的数据乱序现象,但 Flink 可以确保结果的准确性。
使用事件时间可以对数据按事件发生的时间进行排序等操作,从而得到精确的结果。虽然使用处理时间不一定能得到精确结果,但可以满足低延迟的需求。这两种时间语义使 Flink 能够在结果准确性和低延迟之间达到平衡,以满足不同的应用需求。
良好的容错性和故障恢复能力
Apache Flink 具备良好的容错性和故障恢复能力。它可以自动监控任务执行过程中的错误,并在发生故障时进行恢复。这种容错机制保证了长时间运行的大规模数据处理场景下的可靠性,使得 Apache Flink 能够提供稳定可靠的服务。并且,Flink 存储状态采用了轻量级分布式快照,使得状态存储的操作过程是十分轻量的分布式过程。
支持多种一致性语义
Flink 提供了“至少一次”(at least once)语义和“恰好一次”(exactly once)语义的状态一致性保证。它能够确保在发生故障或重新启动时,数据流的一致性得到保障。这样,用户可以放心地进行精确计算和数据操作,而不必担心出现数据不一致的情况。
在外部系统的配合下,Flink 也可以实现端到端的“恰好一次”语义。这意味着在处理数据时,Flink 可以确保每个事件被处理一次且仅一次,这对于避免数据重复或丢失非常重要。
丰富的API和库
Apache Flink 提供了丰富的 API 和库,以支持各种数据处理需求。它支持流处理和批处理,并提供了多个层级的 API 以及易于使用的操作符和函数。用户可以根据实际情况,在追求表达力和追求易用性之间做出权衡,而且不同层级的 API 可以混用,这使得开发人员能够快速开发和调试数据处理逻辑。
此外,Flink 还提供与其他开源生态系统(如Hadoop、Kafka 等)的无缝集成,进一步方便了数据采集、存储和处理的过程。
低延迟、高吞吐量和高可用性
Apache Flink 在处理实时数据时表现出色,具有低延迟和高吞吐量的特性。通过将计算任务分解为多个并行的子任务并进行优化,Flink 实现了快速处理和高效利用资源。这意味着 Flink 可以每秒处理数百万个事件,并且延迟时间仅在毫秒级别。这对于需要在实时数据流中快速做出决策的应用场景非常有用,比如金融市场的交易、物流运输的实时跟踪、实时推荐系统、欺诈检测等。Apache Flink 的高性能保证了实时数据能够在最短的时间内被准确处理。
此外,Flink 也具有高可用性,其本身是高可用的设置,并与Kubernetes、YARN 紧密集成,这使得 Flink 能够以极少的停机时间全天候运行。这种高可用性对于需要不间断运行的应用场景来说至关重要。
小结
Apache Flink 作为一款功能强大、灵活可扩展的流式处理框架,具备多个核心特性,包括流批一体、复杂的状态管理、多种时间语义、良好的容错性和故障恢复能力、支持多种一致性语义、丰富的 API 和库,以及低延迟、高吞吐量和高可用性。
实际上,Flink 的特性远不止这些,还包括丰富的连接器、多平台部署等。这些特性使得 Apache Flink 成为处理实时数据的首选框架,并在各个行业的数据处理需求中广泛应用。使用 Apache Flink,企业可以轻松应对海量数据处理的挑战,实现更高效、更精确的数据计算和操作。
(END)